Expand your search using AWS native services to identify, comprehend and securely store documents.
- Troy Dieter
- Aws
- January 11, 2021
Table Of Contents
The document debacle
Companies continue to fight the battle of the age-old problem: paper documents. Adapting to document modernization to expand the ability to search, catalog and protect HIPAA\PII data is paramount. In this article, we will cover how you can integrate a server-less pipeline within AWS to tackle the document debacle!
Scenario
In the below solution architecture, we will cover data being securely migrated from an on-premise data center to the AWS Cloud. Networking components such as AWS Direct Connect are used to ensure data securely traverses the networking fabric to its destination. The assumption that the data is in a report style format, raw text, Adobe PDF or image based (.PNG, .JPG). This solution can be implemented as a one-time use of a forklift of data, or as replication system in batches over time.
The end-user does not need to be concerned with the process to convert the data, as the server-less pipeline handles all of the data ETL (extract, transform & load). Elasticsearch, when paired with Kibana offers an immensely powerful tool for searching large datasets. It is based on the Apache Lucene engine and is suitable for large document indexing and search capabilities.
Solution overview
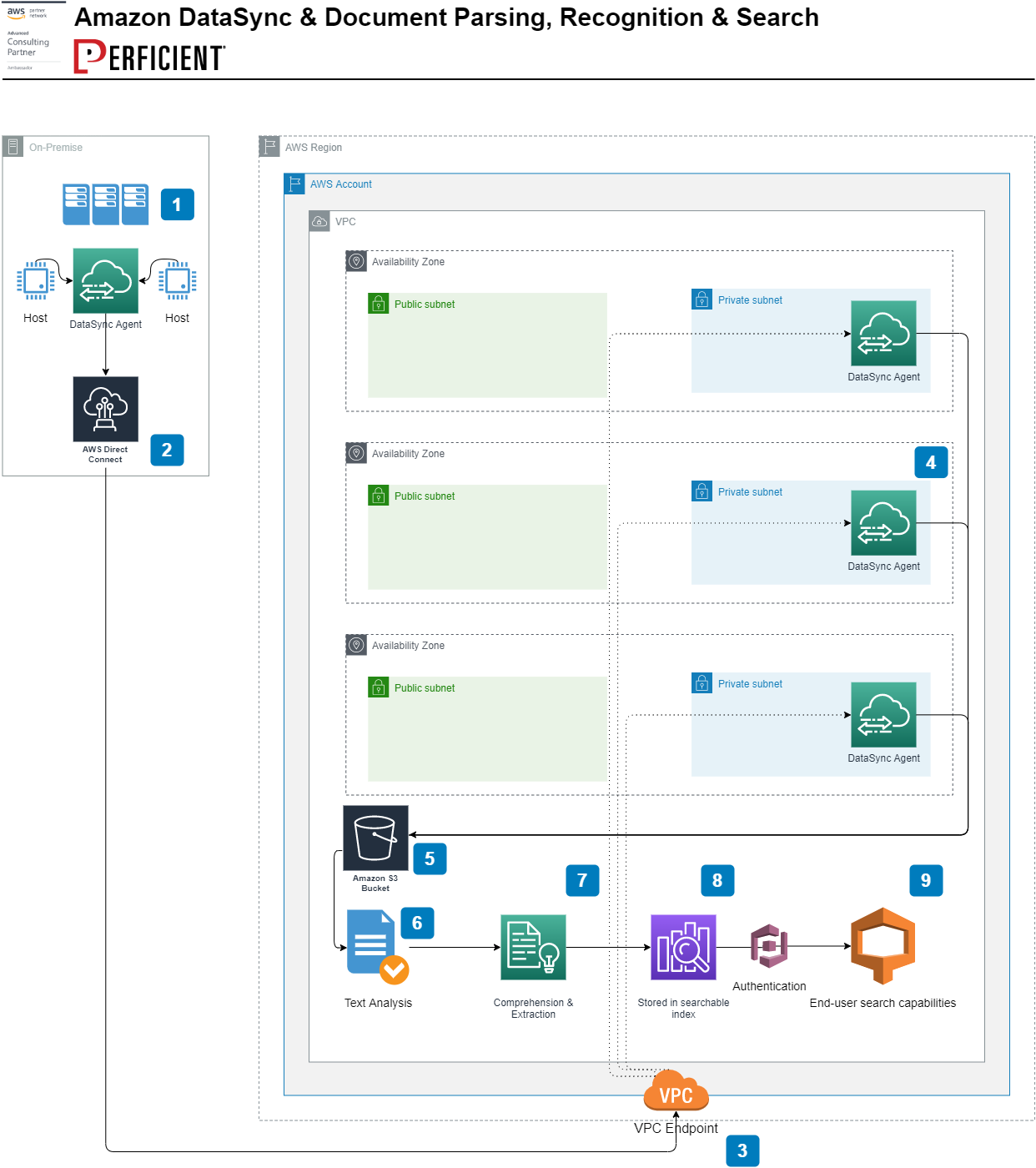
Components
- Data resides on-premise and is in a format supported for conversion. AWS DataSync is deployed to a conventional operating system and is levied to export the data securely.
- Data traverses an AWS Direct Connect to ensure the transit remains private and does not traverse public internet space.
- The VPC endpoint is the ingress point of the VPC, facilitating the secure path.
- The Amazon DataSync service is configured, with agents running in private subnets within the VPC. The DataSync agent will receive the data and process it. In this case, it will be sent to the destination Amazon S3 bucket for processing.
- Data is sent within the VPC (privately) to the Amazon S3 bucket. An Amazon S3 endpoint is used to ensure traffic does not leave the VPC. Objects are encrypted in-flight set by the Amazon S3 bucket policy, while the stored S3 bucket objects are encrypted using AWS KMS encryption at-rest.
- An Amazon Lambda function(s) run to process the data in batches, that have landed in the Amazon S3 bucket. Multiple AWS components facilitate the analysis of the data.
- An Amazon Lambda function(s) run to extract the data in batches, now sent from the previous function. Multiple AWS components facilitate the extraction of the data.
- Amazon ElasticSearch service stores the extracted data in an encrypted (at rest and in transit) index. This data now can be used to be searched internally using the Elasticsearch API or Kibana. Amazon Cognito is used to secure the login process, along with integrating SSO if required.
- Kibana is used to overlay Elasticsearch and provides user friendly search expressions, dashboards and tools.
🔍 Employees can now retrieve records & documents much more easily, while using a single interface!


